VectorDB Benchmarks: Upstash vs Pinecone vs pgvector

In this blog post, we are excited to share our findings from a recent benchmark we ran between Upstash Vector, Pinecone, and pgvector (via Supabase).
We've been wanting to compare Upstash Vector with Pinecone and pgvector for a while now. Finally, we were able to run a series of benchmarks and compare the results.
Upstash Vector is a serverless vector database built for working with vector embeddings for AI models and LLMs.
Pinecone is another fully managed vector database service similar to Upstash Vector.
PGVector is an open-source vector similarity search for PostgreSQL. This extension allows PostgreSQL databases to be used as vector databases for AI applications. Since we are using PostgreSQL, we can use Supabase which is an open-source Firebase alternative.
Why Benchmark Vector Databases?
First of all, we should know what a vector database is. A vector database is a specialized database designed to store, manage, and query/search vector embeddings, which are mathematical representations of data points in a high-dimensional space.
Vector databases are an important part of many AI applications, whether you're building a chatbot or a recommendation system, etc. They offer efficient storage and retrieval of high-dimensional vectors, reducing computational load and speeding up query responses in AI applications.
Therefore it is important that these databases are well-optimized for your specific use case. We wanted to see how Upstash Vector compares to Pinecone and pgvector in terms of performance.
Also cost is a major concern for many developers, rightfully so. We also wanted to see how Upstash Vector compares to Pinecone and Supabase in terms of cost as well.
Benchmark Setup and Methodology
While conducting the benchmarks, we used the amazing benchmarking tool called VSB: Vector Search Bench created by Pinecone. Originally, it was designed for benchmarking Pinecone and pgvector in local databases. We forked the project and added support for Upstash Vector using the upstash-vector Python SDK and pgvector in Supabase with the vecs Python client developed by Supabase.
You can also read their blog post called Pinecone vs. Postgres pgvector: For vector search, easy isn’t so easy which provides great insight for both services.
Supabase also has a great blog post called pgvector vs Pinecone where they compare both services in terms of performance and cost.
Data Sources & Workloads
We used two of the existing workloads available in VSB. These are:
- nq768: (2.6M vectors from Google Natural Questions )
- cohere768: (10M vectors from Cohere-embedded Wikipedia articles)
| Name | Cardinality | Dimensions | Metric | Description |
|---|---|---|---|---|
nq768 | 2,680,893 | 768 | dot product | Natural language questions from Google Research |
cohere768 | 10,000,000 | 768 | cosine | English Wikipedia articles embedded with Cohere from wikipedia-22-12 |
Benchmark Logic and Specific Flags
If you are not planning to replicate these benchmarks or do not want to learn the details behind it, you can skip to the next part.
While upserting vectors into databases, we use batch operations to reduce the number of requests. However, the size of these batches is not fixed. Here is how the batch size (the number of vectors in each request) is calculated:
The code first calculates a size-based batch size based on message size constraints—specifically ensuring the total data won’t exceed the limit. It then compares this computed size-based batch size to a predefined max batch size (in this case, 1000) that might be set for other operational or performance reasons. By taking the minimum of these two values, the system ensures that both conditions are met:
- Not Exceeding the Message Size Limit: The batch fits within the message size constraint.
- Upstash: 10MB
- Pinecone: 2MB
- Staying Within Operational Limits: The batch doesn’t exceed a predefined threshold (defined by service providers).
- Upstash: 1000
- Pinecone: 1000
For Supabase/pgvector, we used the default chunk size of 500 in the vecs Python client.
top_k is 100 for search operations in VSB.
To replicate the benchmark yourself:
- For Upstash, you need to provide the token and the URL of your index before running the benchmark.
- For Pinecone, you need to provide an API key.
- For Supabase/pgvector, you need to provide a connection string to connect to your database.
View Upstash Command
vsb --database=upstash --workload=your_workload \
--upstash_vector_rest_url="<YOUR_UPSTASH_URL>" \
--upstash_vector_rest_token="<YOUR_UPSTASH_TOKEN>" \
--overwriteView Pinecone Command
vsb --database=pinecone --workload=your_workload \
--pinecone_api_key="<YOUR_API_KEY>" \ View Supabase/pgvector Command
vsb --database=supabase --workload=your_workload \
--supabase_connection_string="<YOUR_SUPABASE_CONNECTION_STRING>" \
--overwriteWe created all the vector databases in us-east-1 region and set up a GCP instance in us-central1 region to run the benchmarks.
Since Upstash Vector and Pinecone are serverless, we did not need to configure any settings while creating the databases and running the benchmarks.
For Supabase/pgvector, we used the 8XL compute instance to host the database while indexing and querying which has the following specifications:
- CPU: 32-core ARM (dedicated),
- Memory: 128 GB
- Max DB Size (Recommended): 4 TB
The choice was based on ensuring that the index fits into the maintenance_work_mem variable and for our largest workload cohere768, the index was around 40GBs. Additionally, our database size was approximately 140GBs in total which is way less than the recommended max DB size for this instance. While not running the benchmarks, we changed the compute instance type to the cheapest one (nano) to keep the cost low.
Now, let's see the results!
Results
Performance Comparison
| Workload | Provider | Populate Latency (p99 / p99.9) | Query Latency (p99 / p99.9) | Recall | Population Time |
|---|---|---|---|---|---|
| nq768 (2.6M) | Upstash | 1900ms / 21000ms | 670ms / 1400ms | 0.84 | 1h 47m 11.3s |
| nq768 (2.6M) | Pinecone | 760ms / 11000ms | 260ms / 19000ms | 0.91 | 40m 16.5s |
| nq768 (2.6M) | Supabase pgvector | 4400ms / 4900ms | 1700ms / 2500ms | 0.89 | 5h 31m 9s |
| cohere768 (10M) | Upstash | 1900ms / 4800ms | 2500ms / 4000ms | 0.87 | 4h 44m 41s |
| cohere768 (10M) | Pinecone | 730ms / 1200ms | 360ms / 2200ms | 0.96 | 2h 20m 49s |
| cohere768 (10M) | Supabase pgvector | - | 3000ms / 3500ms | 0.92 | 7h 50m 6s |
You can scroll horizontally to view the full table.
Population is the operation of adding vectors to the database. Index creation is the operation of creating an index in the database which allows for efficient search.
Recall is a measure of how many of the top-k results are relevant to the query. The higher the recall, the more relevant the results are to the query. Recall = TP / (TP + FN) where TP = True Positives and FN = False Negatives.
Graphs
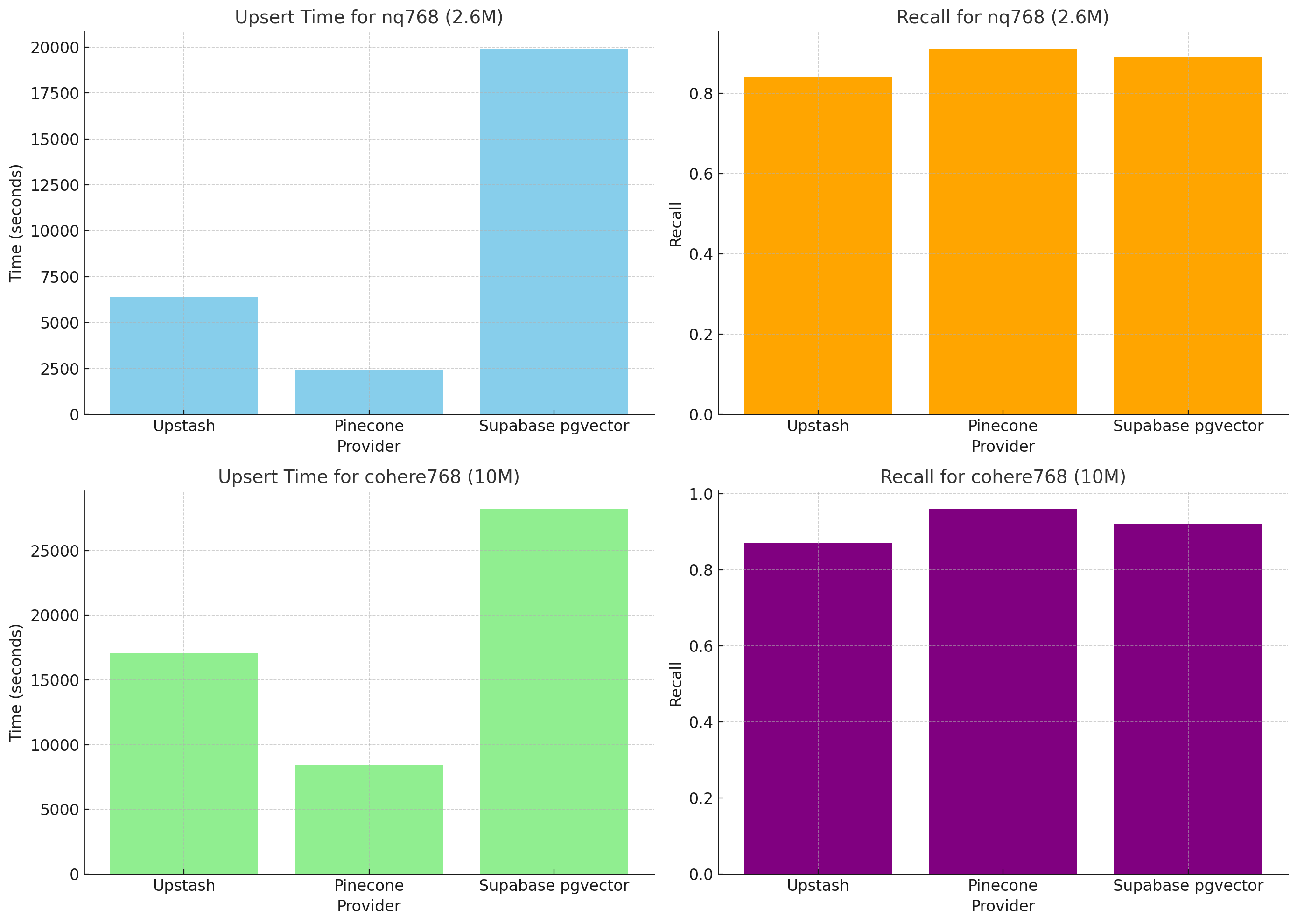
For Supabase/pgvector, we created the index before upserting the data in nq768, and created the index after upserting the data in cohere768. That’s why nq768 took significantly longer to populate the index compared to cohere768. For cohere768, index creation took another hour, which is included in the table and graph above.
Supabase support suggests creating the index before upserting your data because this approach spreads out the time that would otherwise be spend during index creation and is the most reliable.
Cost Comparison
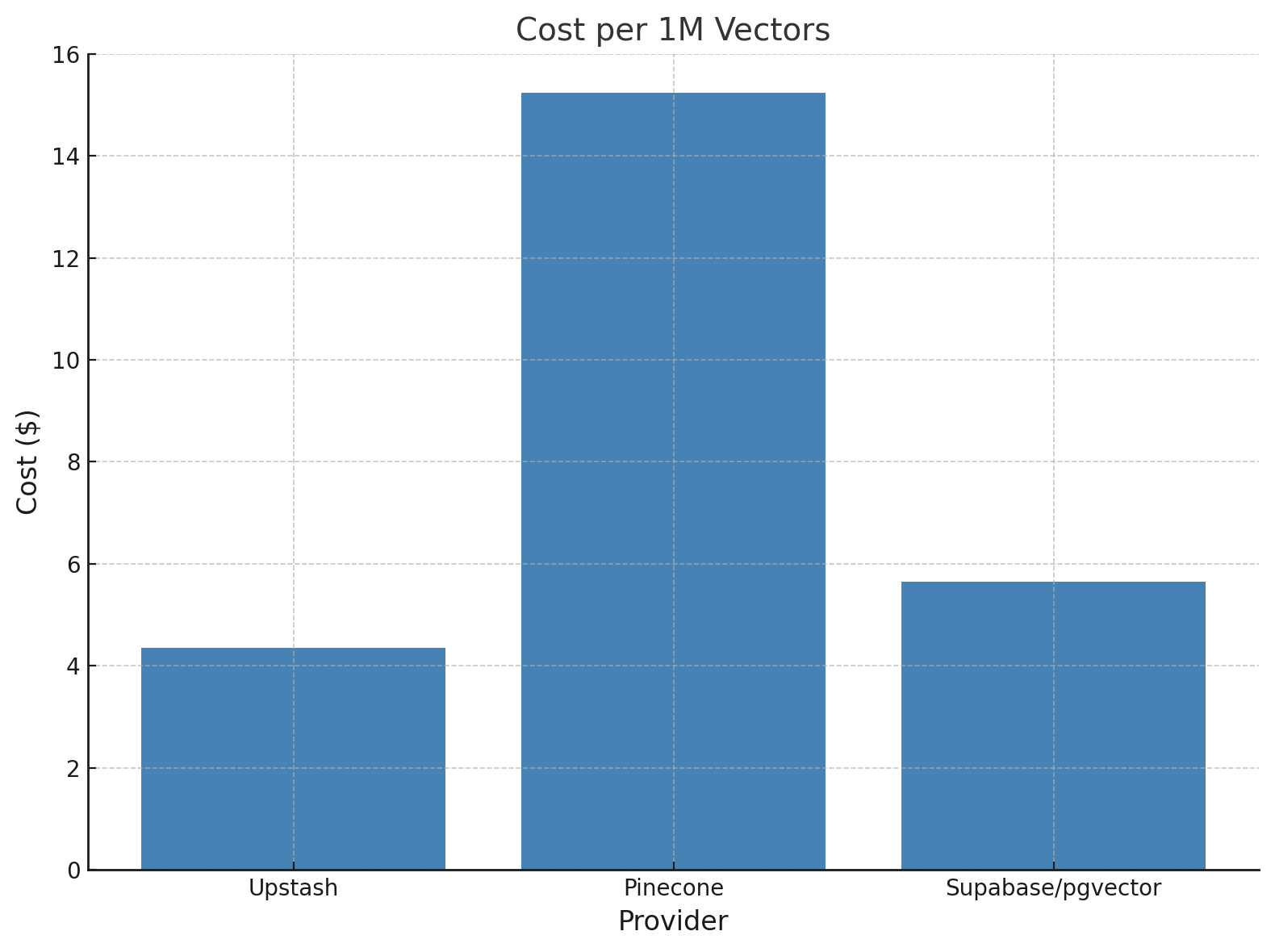
| Provider | Cost per 1M vectors ($) |
|---|---|
| Upstash | ~4.36 |
| Pinecone | ~15.24 |
| Supabase/pgvector | ~5.65 |
We calculated the cost per 1M vectors based on the number of vectors we upserted and the total cost that was reflected to us. Although this includes queries, the number of queries is quite small compared to upserts (a few thousand versus millions), so we might as well just say upserts. Additionally, for Supabase, a Pro account is required, which costs $25 and is included in the calculation.
Key Takeaways
- Upstash Vector is the cheapest and offers good performance.
- Pinecone offers strong performance at a much higher price.
- pgvector in Supabase is cheap and highly configurable, but it's slower and not as easy to use as the other services.
Observations & Challenges
While benchmarking, we once again noticed how easy it is to use serverless services compared to others. In our case, we constantly needed to change our compute instance type to match the workload, all while trying to keep costs low in Supabase. This is because in pgvector, the index needs to fit in RAM; otherwise, the build throughput drops sharply. Here is a quote from the Pinecone blog post about this:
For building an index in Supabase with pgvector, you need to make sure that the entire index fits into your RAM, once the index exceeds RAM the build throughput drops precipitously — over 10x slower. This is because the HNSW graph has exceeded the working memory, and needs to spill to disk to continue to build the index. As such it’s not feasible to rely on Postgres’s ability to page from disk during index builds and maintain quick build times.
Also, the disk size must be increased to match the workload size, and you can’t accurately estimate the size of the index beforehand in pgvector. Here is another quote from the Pinecone blog post on this:
The “expansion factor” — the ratio of the index RAM to the original dataset — varies significantly across the different datasets. This is counterintuitive: there is no simple way to figure out how to size the index’s working set memory, and the consequences of getting this wrong are significant.
Additionally, deciding when to create an index in Supabase/pgvector is crucial. The index can be built before or after upserting. If you create it before upserting, the time it takes to populate the index increases significantly. In our benchmarks, it took three times longer to populate the index using the nq768 workload. However, if you create the index after upserting, the index creation may fail since it’s a resource-intensive task requiring a persistent connection to the database. Here is a useful guide on index creation in Supabase/pgvector. As mentioned in that guide, you need to configure parameters like maintenance_work_mem and max_parallel_maintenance_workers to create the index efficiently.
On the positive side, the ability to configure the index in Supabase/pgvector means you can tweak parameters such as the maximum number of connections per layer and the size of the dynamic candidate list for constructing the graph. To learn more about these configurations in pgvector, you can read the pgvector README which is the best place to start if you want to learn more about pgvector.
Conclusion
Summary: Upstash Vector, while being significantly cheaper, is slower than Pinecone. Compared to pgvector in Supabase, it is similar in cost but significantly easier to use and faster. Additionally, all the databases have good recall scores but Upstash Vector is trailing behind Pinecone and pgvector in terms of recall scores.
These benchmarks show us where we can still improve, and we are very determined to give the best experience to developers. As proof of this commitment, we recently shipped sparse and hybrid index support for Upstash Vector. We have even more exciting plans for the future.
To learn more about Upstash Vector, please check out the documentation. You can also reach out to us through Discord if you have any questions.